String의 구성 - Character, Unicode, Index
23 May 2019 |
String의 구성 - Character, Unicode Scalar, Index
 Table Of Contents
Table Of Contents
- String in swift
- Unicode
- unicode scalar
- String element 세기 - Index
String in swift
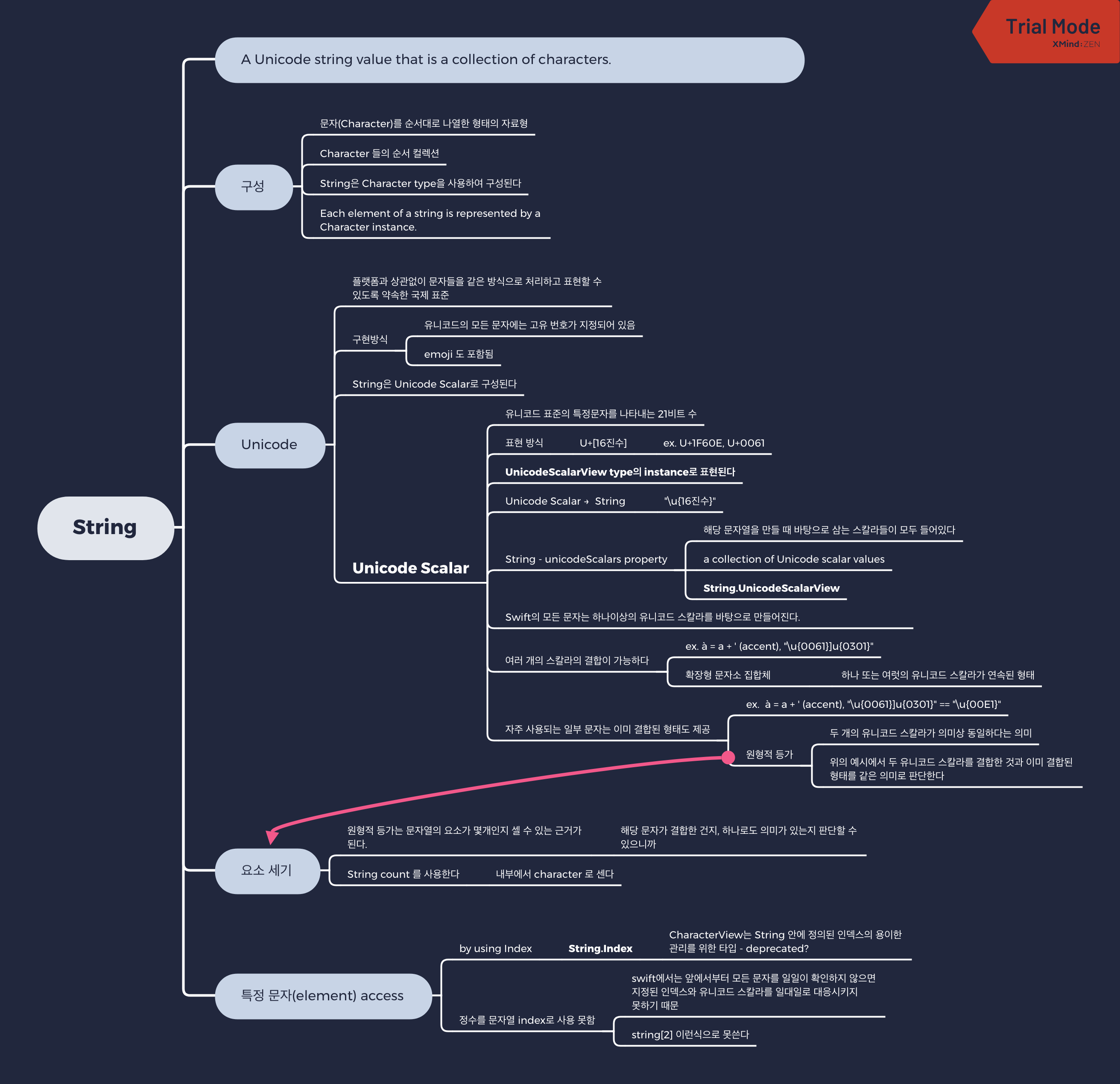
a Unicode String value that is collection of characters (swift api)
string은 일련의 character들의 모음이다.
swift에서 String을 구성하는 문자는 Character type을 사용한다. 주로 유니코드 문자를 나타낼 때 Character type을 사용하고, Character type을 조합하면 String 타입이 된다
따라서 String을 구성하는 각각의 element는 Character instance 이다.
StringProtocol protocol
-
String으로 표현될 수 있는 type의 자격요건을 명시한 protocol -
Charactercollection으로 String을 표현할 수 있는 능력을 명시한다 -
해당 프로토콜을 준수하는 타입:
String,SubString
Unicode
플랫폼과 상관없이 문자를 같은 방식으로 표현하고 처리할 수 있도록 약속한 국제 표준
모든 문자에는 유니코드에서 약속한 숫자가 부여(매핑)되고, 문자를 해석할 때, 해당 숫자로 구분한다. 유니코드에는 emoji 도 포함된다.
유니코드는 index와 문자를 매핑한다고 설명하기도 한다. index의 의미는 아마 문자 순서대로 숫자가 커지니까 그런 것이 아닐까 생각해봤다.
'A' : index 0x0041, U+0041
String 과 Character type은 이 unicode를 바탕으로 만들어졌다.
구체적으로는 문자열은 unicode scalar로 구성되어 있다.
Unicode Encoding 방식
인코딩 방식에는 2가지 - UTF, UCS 가 있다
- UTF(Universal Transformation Format) : 몇 bit 단위를 사용해서 index를 표현할 건지
- ex. UTF-8 : 8bit 씩 늘려가며 index를 표현한다
- UCS(Universal Character Set) : 몇 byte 단위 를 사용해서 index를 표현할 건지
- ex. UCS-2 : 2 byte씩 늘려가며 index를 표현한다.
UTF -
- UTF 뒤에 붙는 숫자는 인코딩 방식(저장방식)의 차이를 나타낸다.
- 기본적으로 utf 문자는 32bit(4byte) 크기의 사이즈 안에 표현한다.
-
uft는 가변 길이 문자 인코딩 방식
- 인덱스가 커짐에 따라 인덱스를 표현하는 비트도 늘어난다는 뜻
- 문자를 표현하는데 필요한 비트만 사용한다
- 인덱스가 커지면서 더 많은 비트가 필요하면 단위 비트만큼 늘려가면서 표현한다
- utf 뒤에 붙는 숫자는 코드 단위로, 그 숫자의 bit 만큼씩 문자 표현 부분이 늘어난다는 것이다.
-
종류

-
UTF-8 : 기본 8bit 를 쓰고, 그보다 인덱스가 크면 2byte, 3byte, 4byte 로 늘려가며 표현
- 영어 알파벳의 경우 256(2^8) 안에 다 표현 가능하므로 1byte 안에 표현이 가능
- 그 이외의 문자는 더 큰 더 많은 비트를 필요로 한다
-
UTF-16 : 기본 16 bit를 쓰고, 2byte, 4byte로 늘려간다
- 예전에는 16bit로 모든 문자를 표현 가능했다. 이 때의 문자 셋을 BMP(Basic Multilingual Plane)라 한다
- 점차 문자가 늘어나면서 16bit로 표현 못하는 문자도 생겼다.
- BMP보다 index가 높은 문자는 32bit를 사용해서 표현한다.
-
UTF-32 : 기본적으로 모든 문자를 32byte 에 표현한다
- 8, 16 처럼 늘려가는 처리가 불필요
-
UTF-8 : 기본 8bit 를 쓰고, 그보다 인덱스가 크면 2byte, 3byte, 4byte 로 늘려가며 표현
Unicode Scalar
유니코드 표준을 따르며, 특정문자를 나타내는 21비트 수
-
Swift의
String,Character는 유니코드 표준을 따른다. -
String은 여러개의 unicode scalar 로 구성되어 있다.
A string is a collection of extended grapheme clusters, which approximate human-readable characters. Many individual characters, such as “é”, “김”, and “🇮🇳”, can be made up of multiple Unicode scalar values. These scalar values are combined by Unicode’s boundary algorithms into extended grapheme clusters, represented by the Swift
Charactertype. Each element of a string is represented by aCharacterinstance. (출처 - Apple Documentation String 공식 문서)
-
String구조체는unicodeScalarsproperty 를 가진다- 이는
UnicodeScalarViewtype 이다 - == a collection of unicode scalar values
var unicodeScalars: String.UnicodeScalarView // The string’s value represented as a collection of Unicode scalar values. - 이는
-
String 을 unicode로 변환한 내용을 property로 제공한다
-
unicodeScalars,utf16, orutf8properties.
-
-
String에 unicode index로 문자를 표현하는 방법 :
"\u{16진수}"let cafe = "Cafe\u{301} du 🌍" print(cafe) // Prints "Café du 🌍" -
내가 보기엔 문자 1개 인 것 같아도, 한 개의 character 는 한 개 이상의 unicode scalar로 구성되어 있을 수 있다.
"é" = "e" + "`"("\u{301}")-
String.count와String.unicodeScalars.count가 다를 수 있다 - String.count : Character instance 의 개수
let cafe = "Cafe\u{301} du 🌍" print(cafe) // Prints "Café du 🌍" print(cafe.count) // Prints "9" print(cafe.unicodeScalars.count) // Prints "10" print(Array(cafe)) // Prints "["C", "a", "f", "é", " ", "d", "u", " ", "🌍"]" print(Array(cafe.unicodeScalars)) // Prints "["C", "a", "f", "e", "\u{0301}", " ", "d", "u", " ", "\u{0001F30D}"]" print(cafe.unicodeScalars.map { $0.value }) // Prints "[67, 97, 102, 101, 769, 32, 100, 117, 32, 127757]" -
-
원형적 등가 : 두 개의 유니코드 스칼라가 의미상 동일하다는 의미
- 유니코드 스칼라 두개 합친 형태를 아예 새로운 하나의 유니코드 스칼라로 표현할 수 있는 경우도 있음
- 이런 경우, 두 개의 유니코드 스칼라를 합친 것과 한개의 유니코드 스칼라는 같은 의미로 판단한다. 이를 원형적 등가라고 함
à = a + ' (accent), "\u{0061}]u{0301}" == "\u{00E1}"
String.Index
-
String의 각 element에 접근하는 방법
- subscript
[]&Indextype으로 접근
- subscript
[]와 정수값 index로 접근
let message = "Happy B-day" let firstIndex = message.startIndex //String.Index type print(message[firstIndex]) // H print(message[0]) // error - subscript
-
정수 값을 index로 사용할 수 없는 이유
- String은 unicode scalar로 구성되어 있는데, 한 character가 한 개 이상의 unicode scalar의 합성으로 이루진 경우가 있음
- 따라서 앞에서부터 세봐야 index를 알 수 있음. 이 과정을 내부적으로 처리해주는게 String.Index 구조체
Reference
- 빅 너드 랜치의 스위프트 프로그래밍
- Apple documentation - String
- Apple documentation - UnicodeScalarView
- 유니코드 관련